Base de Données ou Statique
Pendant longtemps, nous avons vécu dans un monde où nous utilisons des approches par défaut sans vraiment réfléchir à leur objectif. Prenons WordPress comme exemple : c'est une application puissante, mais elle nécessite MySQL comme base de données, et pour la rendre rapide, vous avez souvent besoin de Memcache pour mettre en cache les requêtes MySQL et réduire la charge sur la base de données. À côté, il y a l'éditeur WYSIWYG qui, en théorie, permet aux utilisateurs d'éditer facilement le HTML, mais qui, en pratique, génère souvent un code illisible et encombrant.
Mais la question fondamentale est : pourquoi faisons-nous cela ? Nous installons WordPress, MySQL et Memcache pour générer essentiellement des pages "statiques" car WordPress peut être lent, et les mises à jour de contenu sont rares. Pour chaque page générée :
- Un site WordPress basique effectue 10 à 30 requêtes.
- Un site modérément complexe avec quelques plugins et un thème populaire : 30 à 60 requêtes.
- Un site très complexe avec de nombreux plugins et des thèmes lourds peut effectuer 60 à 100+ requêtes.
Même un simple billet de blog peut nécessiter entre 10 et 100+ requêtes, ce qui explique pourquoi les sites WordPress peuvent être lents.
Pourquoi Restons-nous avec WordPress ?
La grande question demeure : Pourquoi utilisons-nous un système aussi compliqué ? Historiquement, l'utilisation d'une base de données relationnelle comme MySQL pour un blog avait du sens car les gens pouvaient laisser des commentaires, et les bases de données offraient un moyen rapide de stocker et de récupérer ces informations. Mais aujourd'hui, peu de sites WordPress ont les commentaires activés à cause du spam incessant qui les accompagne souvent. En conséquence, la plupart des sites s'appuient sur des solutions tierces comme Disqus ou Facebook Comments pour gérer les commentaires des utilisateurs. Ces services prennent en charge la vérification des utilisateurs et le filtrage du spam, ce qui signifie que nous n'avons plus besoin de la base de données pour fournir du contenu dynamique sous forme de commentaires.
Une Approche Statique
Chez True, nous avons opté pour une approche entièrement statique. Nous utilisons des fichiers statiques comme notre "base de données" :
- blog.php gère les pages de blog.
- support.php gère les pages de support (historiquement différentes mais maintenant similaires en format).
- categories.php gère la liste des catégories dans le menu supérieur et la barre latérale.
Nous stockons l'ensemble de la base de données du blog sous forme de simples fichiers PHP ou JSON, ce qui est efficace car nous utilisons PHP pour faire fonctionner notre site.
Voici comment cela fonctionne :
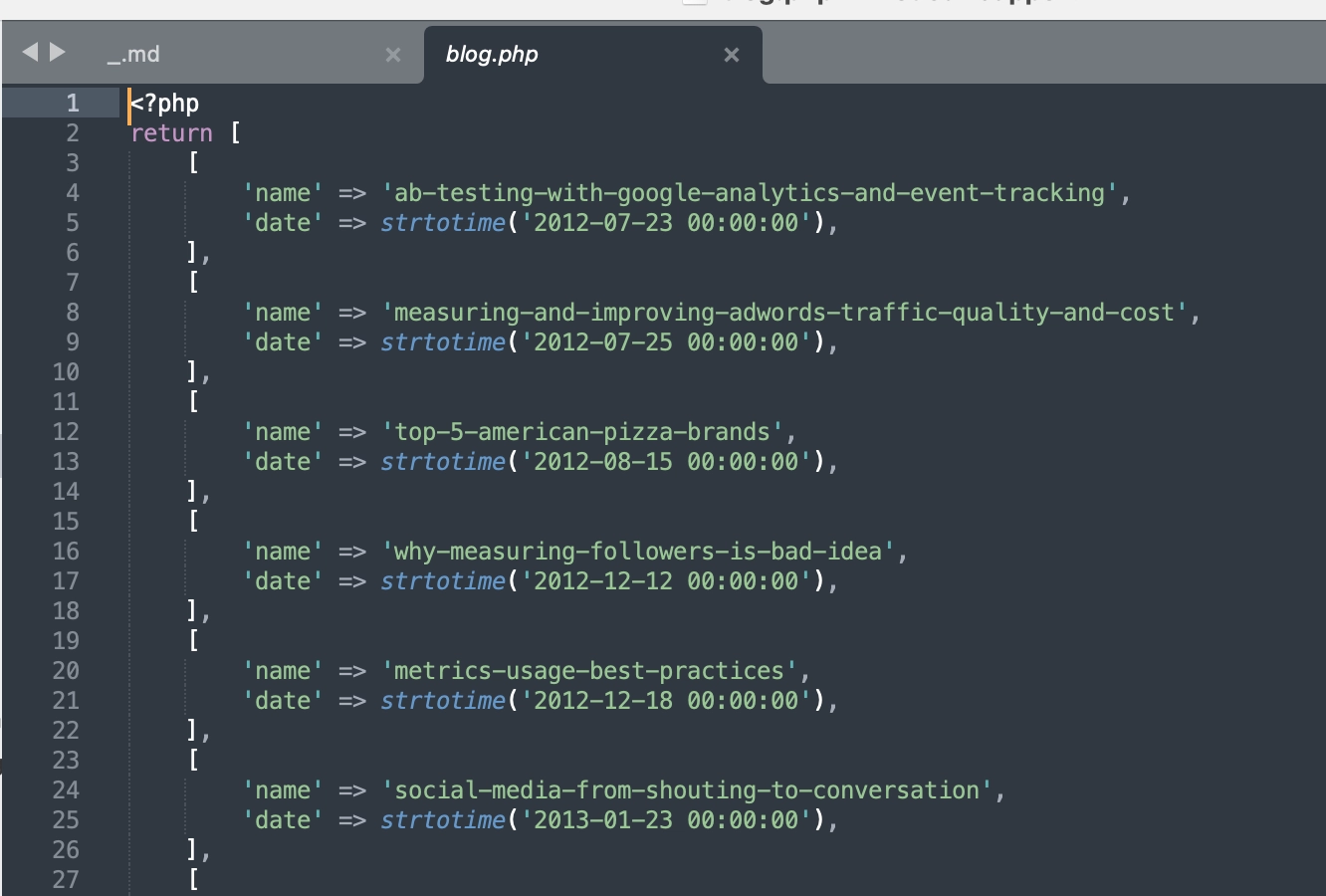
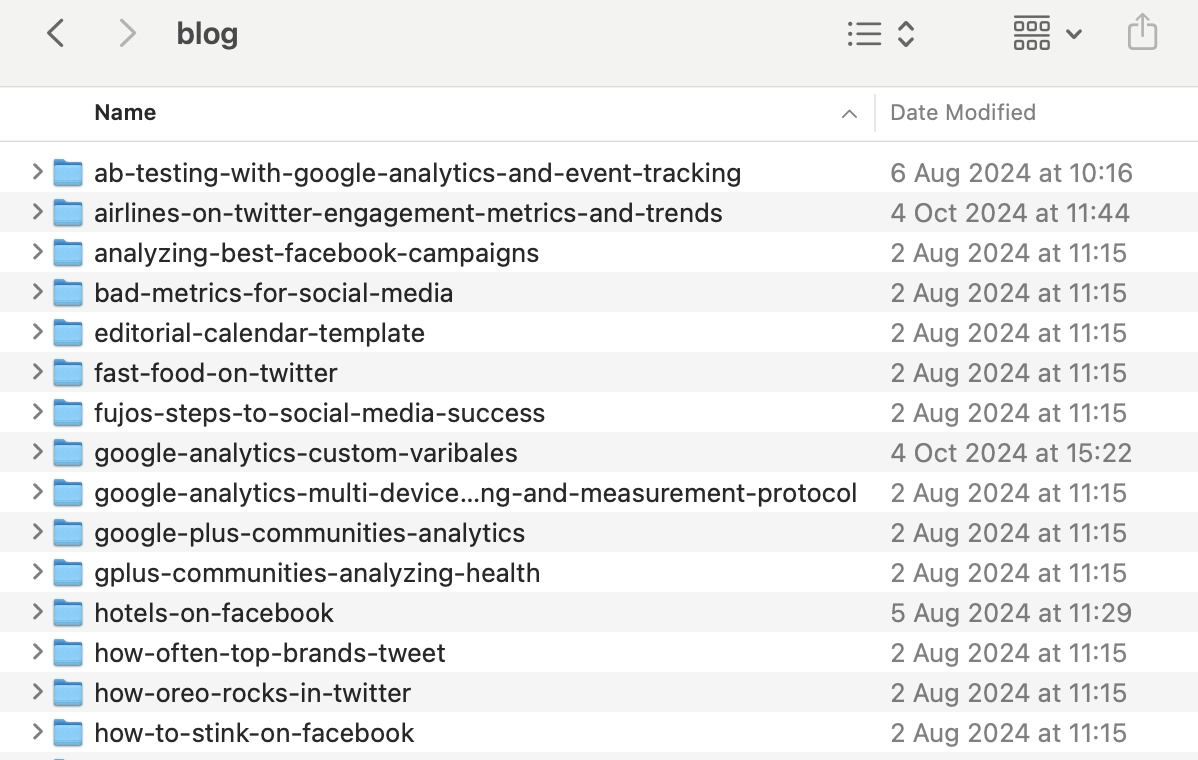
Chaque entrée de blog est stockée sous forme de dossier contenant un fichier markdown (_.md) et des ressources associées comme des images et des pièces jointes.
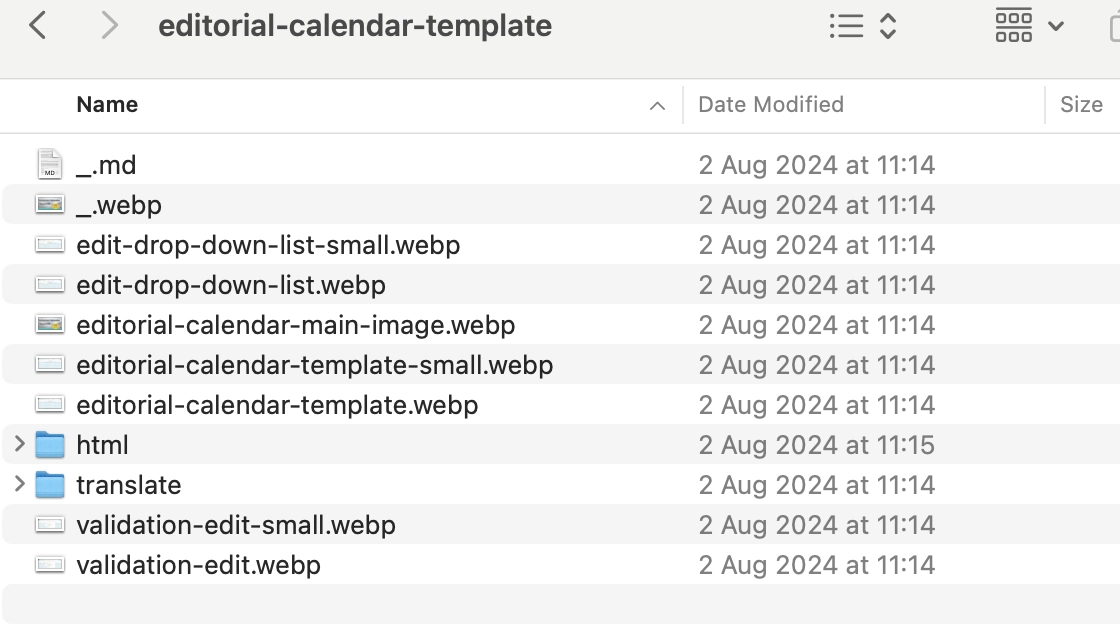
Nous avons également deux dossiers supplémentaires pour :
- Traduire : Stocke les traductions des fichiers markdown dans différents paramètres régionaux (par exemple, es_ES, de_DE).
- HTML : Contient les fichiers HTML générés à partir du markdown, qui sont régénérés à chaque déploiement.
La magie opère pendant le processus de déploiement. Nous utilisons Composer pour déclencher la transformation du markdown en HTML via des scripts :
"scripts": {
"post-install-cmd": [
"php bin/markdown-to-html.php"
],
"post-update-cmd": [
"php bin/markdown-to-html.php"
]
}
Le meilleur outil que nous avons trouvé pour la transformation du markdown est league/commonmark, qui apporte des plugins utiles, y compris la prise en charge des tableaux et des chemins CDN personnalisés pour nos images.
Déploiement
Nous utilisons un processus de déploiement basé sur GitHub Actions et Deployer, qui a été facile à intégrer. Voici un exemple de script :
name: Deploy
on:
push:
branches: [ "main" ]
concurrency: production_environment
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: "8.3"
- name: Deploy
uses: deployphp/action@v1
with:
private-key: ${{ secrets.PRIVATE_KEY }}
dep: deploy
verbosity: -vvv
Le processus est simple : chaque fois que quelqu'un fait un commit sur la branche “main”, le déploiement se fait automatiquement. Les actions durant le déploiement incluent :
- Copier les images dans le dossier
public/img. - Générer une carte de hachage pour toutes les images et pièces jointes.
- Générer HTML à partir des fichiers markdown en :
• Corrigeant les chemins des images (par ex. de
/img/blog/...àcdn.truesocialmetrics.com/img/blog/...). • Mettre à jour les chemins CDN si nécessaire.
Pendant la génération HTML, les présentations, en-têtes et menus sont également ajoutés. C'est ainsi que nous servons des fichiers statiques qui peuvent sembler dynamiques pour les utilisateurs.
Avantages D'une Approche Statique
Performance
Les sites statiques sont incroyablement rapides, avec des temps de chargement de page aussi bas que 3-5 ms.
Simplicité
Enseigner à notre équipe de support à utiliser Markdown est beaucoup plus facile que de les former à naviguer dans un CMS complexe comme WordPress.
Code Propre
En contrôlant le processus de transformation du markdown en HTML, nous garantissons que le HTML résultant est propre et optimisé pour les moteurs de recherche (bonjour, Google !) et les fonctionnalités comme la “Vue Lecteur” dans les navigateurs.
Maintenabilité
Puisque nous utilisons des fichiers statiques et Git pour le contrôle de version, chaque changement est suivi automatiquement, jusqu'à chaque ligne. Les pièces jointes comme les images bénéficient également du contrôle de version, ce qui permet de savoir qui a fait une modification et pourquoi. Cela rend la recherche et la modification de contenu efficaces, en utilisant des outils comme grep et ack.
Accessibilité Pour l'Équipe
Notre équipe trouve la structure statique facile à utiliser, surtout avec des outils comme GitHub Desktop et Typora, un éditeur markdown beau et simple.
Conclusion
En essence, nous nous sommes éloignés de l'approche traditionnelle basée sur les bases de données qui domine les plateformes comme WordPress. En utilisant un système statique, nous avons non seulement amélioré la performance mais aussi simplifié la maintenance, la création de contenu et la collaboration en équipe.
Lorsque vous êtes prêt à faire vibrer vos analyses de médias sociaux
essayez TrueSocialMetrics!
Commencer procès
Pas de carte de crédit nécessaire.
continuer la lecture
Top 5 des marques de pizzas américaines sur les réseaux sociaux

Le type d'épingles le plus viral : Barney's sur Pinterest

10 conseils pour commencer à créer du contenu incroyable dès maintenant

Comment puer sur Facebook avec 17 millions d'abonnés : Apprenez de Burberry
